Spring Boot Starter
1. Le protocole HTTP
1.1. Modèle d’architecture
Le modèle traditionnel d’architecture des applications web est de type 3 tiers (clients, serveur(s), SBBD(s)), chaque tiers étant, par définition, positionné sur des matériels différents, éloignés les uns des autres mais reliés par des connexions réseaux.

Les applications se situent sur le tiers du milieu, sur le "server d’applications" (derrière un serveur HTTP le plus souvent).
En environnement de développement, les développeurs disposent d’un internal web server, un serveur http intégré à leur IDE. Dans le cadre d’application écrite en Java, c’est le serveur d’application Apache Tomcat, qui est souvent utilisé pour les tests (en phase de développement).
En environnement de production, l’application pourra être déployée avec un serveur web intégré (tomcat) ou derrière un server d’applications existant.
1.2. Interaction Client <→ Application
Conformément au modèle d’architecture 3 tiers web, le client utilise le protocole HTTP[1] pour interagir avec l’application web. Le client web le plus populaire est le navigateur Web.
HTTP (Hyper Text Transfert Protocol) a été inventé par Tim Berners-Lee, il définit la façon dont un serveur et un client web échangent des informations. HTTP ne définit ni le format des informations transférées (HTML, GIF, JPEG, …) ni le mode de construction des adresses Web (URLs) qui font l’objet de documents de normalisation à part.
HTTP définit un ensemble de commandes permettant l’interaction entre un client et un serveur qui supportent le protocole. HTTP est un procole déconnecté ou sans état ce qui signifie qu’il n’assure pas le suivi d’un dialogue entre le client et le serveur. HTTP est définit au-dessus de TCP qui est un protocole connecté et utilise le port TCP 80.
Avec HTTP le client initie le dialogue en envoyant une requête à l’application, le serveur répond au client et coupe la communication (HTTP/1.0).

COMMANDE URI VERSION En-tête de la requête éventuellement sur plusieurs lignes [ligne vide] Corps de la requête sur plusieurs lignes si nécessaire
GET / HTTP/1.1 Host: www2.vinci-melun.org User-Agent: curl/7.54.0 Accept: */*
VERSION CODE-REPONSE TEXTE-REPONSE entête de réponse sur plusieurs lignes si nécessaire [ligne vide] corps de la réponse sur autant de lignes que nécessaire
HTTP/1.1 200 OK Date: Fri, 24 Nov 2017 17:10:31 GMT Server: Apache/2.4.10 (Debian) Set-Cookie: PHPSESSID=8rkmkmu65saa92q0b7vig0mg51; path=/ Expires: Thu, 19 Nov 1981 08:52:00 GMT Cache-Control: no-store, no-cache, must-revalidate, post-check=0, pre-check=0 Pragma: no-cache Link: <http://www2.vinci-melun.org/wp-json/>; rel="https://api.w.org/" Link: <https://wp.me/P8ik5n-ba>; rel=shortlink Vary: Accept-Encoding Transfer-Encoding: chunked Content-Type: text/html; charset=UTF-8 <!DOCTYPE html> <html class="no-js" lang="fr-FR" > <head> .... </html>
1.3. Les commandes
Les commandes les plus utlisées sont par les navigateurs sont GET, POST et HEAD, les applications
REST font également usage de PUT et DELETE.
1.3.1. GET
Permet de récupérer une ressource depuis une URI sur le serveur. Cette URI peut faire penser à un chemin d’accès à un fichier et c’est souvent le cas côté serveur, mais ce n’est pas une obligation, loin de là
Il est toujours possible de passer des paramêtres au serveur via une requête GET, mais ces paramètres apparaissent dans l’URL. Une URL avec des paramêtres a la forme suivante :
http://127.0.0.1/user?id=1274
Tous les éléments après le ? sont des paramètres de la requête, le ? lui-même n’en fait pas partie,
c’est un délimiteur. Même s’il n’y a pas de norme sur la structure exacte
de la requête la forme la plus courante est clé=valeur pour un paramètre. S’il y a plusieurs paramètres
les paires clé=valeur sont séparés par des esperluettes &. Par exemple :
http://127.0.0.1/chercher?cpost=77000&categorie=5
Les caractères autorisés dans la chaîne de requête sont :
-
[A-Z] -
[a-z] -
[0-9] -
*,-,.et_ -
Les autres caractères sont remplacés par leur équivalent numérique hexadécimal précédé du signe
%, par exemple@est codé%40et+est codé%2B
Le résultat d’une
requête GET ou HEAD devrait pouvoir être mis en cache sauf si l’en-tête de
réponse Cache-header
en décide autrement.
1.3.2. HEAD
La commande HEAD permet de récupérer l’en-tête correspondant à une ressource la réponse
est identique à celle d’une réponse à une commande GET, mais sans les données.
1.4. Travaux pratiques
1.4.1. Prérequis
-
curl opérationnel sur votre système
-
une petite application web opérationnelle : http://51.68.231.195:8080/hello (dont on peut obtenir le code ici)
| cURL (abréviation de client URL request library : « bibliothèque de requêtes aux URL pour les clients » ou see URL : « voir URL ») est une interface en ligne de commande, écrite en C, destinée à récupérer le contenu d’une ressource accessible par un réseau informatique. https://fr.wikipedia.org/wiki/CURL |
1.4.2. Test de l’application
Plusieurs façons de tester l’application
http://51.68.231.195:8080
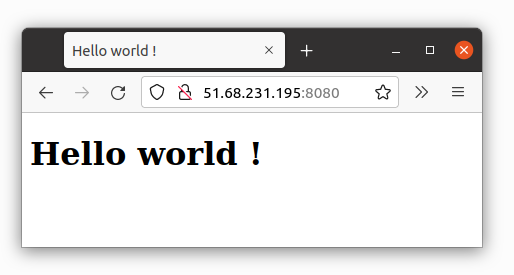
curl http://51.68.231.195:8080
Vous recevez le texte (code source html) de la réponse (le même que reçoit le navigateur)
1.4.3. Challenge
À l’aide de votre navigateur, tester la route suivante :
http://51.68.231.195:8080/hello
Puis la route suivante, paramétrée :
http://51.68.231.195:8080/hello?nom=Django
Puis, de nouveau la route suivante, sans paramètre :
http://51.68.231.195:8080/hello
Normalement le serveur s’est rappelé de votre dernière requête.
1.5. Techniques de suivi de sessions HTTP
Rappel : HTTP est un protocole sans état
Conséquence : un serveur HTTP n’a pas les moyens (via le protocole HTTP) de reconnaître une séquence de requêtes provenant d’un même client. L’adresse IP n’est pas suffisante pour identifier un client parce qu’elle peut faire référence à un serveur proxy sortant par exemple.
Problème : Beaucoup d’applications web doivent gérer des états. Exemple : formulaire multi-pages, gestion d’un caddie, d’une session utilisateur.
Pour contourner ce problème, des données d’état doivent transiter entre les clients et le serveur et être sauvegardées sur un de ces deux tiers. C’est un des aspects très sensible, en terme de cybersécurité, du protocole HTTP.
Voici les solutions les plus courantes pour réaliser un suivi de sessions utilisateur.
| Solution | Données portées par le client | Données portées par le serveur |
|---|---|---|
Champs cachés de formulaire |
x |
|
Réécriture de l’URL |
x |
|
Cookies persistants |
x |
|
API de suivi de session par identifiant de session |
x |
x |
1.5.1. Champs de formulaire cachés
L’utilisation de champs de formulaire cachés permet au serveur de transmettre des informations au client qu’il retransmet au serveur de façon transparente. Exemple :
<form name='formcaddie1' onSubmit='return checkdata()'>
<input type='hidden' name='code' value='3'>
<input type='hidden' name='niveau' value='expert'>
<input type='hidden' name='user' value='julien'>
...
<input type='text' name='quantiteprod' size='3'>
<p><input type='submit' value='valider' name='valider'>
</form>1.5.2. Réécriture de l’URL
L’idée consiste à placer des paramètres dans les URLs renvoyées à l’utilisateur sous forme de liens <a href='construction dynamique'> lien </a>
afin d’assurer le suivi de session.
Par exemple :
<a href='/listerProduits?user=julien&categorie=classique'> lien </a>1.5.3. Cookies HTTP
Intégré au protocole HTTP, un cookie est un ensemble de données texte enregistré sur le poste client qui contient des informations initialement transmises par un serveur web à un navigateur.
Un cookie à une portée (domaine) et une durée de vie. Voir cookie
Lorsqu’un navigateur reçoit en entête HTTP l’instruction (Set-Cookie: nom=valeur), le couple clé=valeur est sauvé sur disque et le renvoie systématiquement, à chaque nouvelle
requête HTTP du client (dans l’entête HTTP Cookie: nom=valeur), au serveur (l’application web) à l’origine du cookie.
GET / HTTP/1.1 Host: www.exemple.org ... HTTP/1.1 200 OK Content-type: text/html Set-Cookie: name=value ... GET /page.html HTTP/1.1 Host: www.exemple.org Cookie: name=value ...
1.5.4. API de suivi de session par identifiant de session
Le dispositif de suivi de session est un mécanisme automatique, déclenché coté serveur ; un identifiant de session est alors généré qui sera stocké à la fois sur le serveur et sur le client, ce dernier aura la responsabilité de le transmettre au serveur lors de chacune de ses requêtes à ce même serveur (par cookie ou paramètre d’url).
L’identifiant de session est une valeur arbitraire qui permet d’identifier (côté serveur) un utilisateur d’un autre. L’identifiant de session fait alors office de clé d’accès à des informations personnelles à une session (un utilisateur). Ces informations sont stockées sur le serveur (en mémoire, fichiers texte ou dans une base de données)
La création de ce type d’identifiant et la technique de transmission (par url ou par cookie) sont pris
en charge par les outils de développement web (sous la forme d’une librairie ou d’une classe Session).
Le développeur ne manipule que rarement l’id de session; l’accès aux données de session s’opère le plus
souvent via une structure de type dictionnaire (ensemble de couples clé/valeur).
2. Introduction
2.1. Spring
Spring, un framework java pour les applications connectées, rend la programmation Kotlin/Java plus rapide, plus facile et plus sûre pour tout le monde. L’orientation de Spring sur la vitesse, la simplicité et la productivité en a fait l’un des plus populaires framework Java.
On retrouve Spring dans tous les contextes : depuis les sites de commerce en ligne jusqu’aux voitures connectées, en passant par les applications de streaming TV et bien d’autres applications.
Spring est un ensemble d’extensions et de bibliothèques tierces intégrées qui permet de bâtir à peu près n’importe quel type d’applicaton. Au coeur de Spring on retrouve l’Inversion de Contôle (Inversion of Control, IoC) et l’Injection de dépendances (Dependency Injection, DI), ces deux caractéristiques sont à la base d’un grand nombre d’autres caractéristiques et fonctionnalités.
Une application Spring classique est relativement difficile à mettre en oeuvre et demande une expertise certaine pour définir l’ossature et les fichiers de configuration.
Spring Boot est une version de Spring basé sur le principe d'auto-configuration, plus facile à mettre en oeuvre tout en offrant les mêmes avantages que Spring. Spring Boot évite notamment les fichiers de configuration XML complexes. Par ailleurs, Kotlin simplifie la syntaxe et renforce la cohérence et sureté du code.
2.2. Spring Boot
Spring Boot est une version de Spring qui privilégie les conventions plutôt que les configurations (convention over configuration), à savoir que si le développeur respecte un certain nombre de normes comme le nommage, le placement des fichiers de code, les annotations, … il peut s’affranchir d’un grand nombre de fichiers de configuration. Spring fournit même un site dédié qui permet de générer un squelette d’application, https://start.spring.io, connu également sous le nom de Spring Initializr.
2.2.1. Spring Boot c’est :
-
Un outil de construction rapide de projets Spring
-
L’intégration des nombreux sous-projets Spring
-
La possibilité de choisir entre plusieurs technologies pour la persistance, la logique applicative ou la gestion des vues. Plusieurs technologies peuvent cohabiter
-
L’assurance de toujours avoir les bonnes dépendances
-
Etre prêt à commencer à programmer en quelques minutes
-
-
Une vision convention plutôt que configuration
-
L’application est prévue pour fonctionner avec un ensemble cohérents de paramètres par défaut
-
La configuration et la dépendance entre beans se fait principalement par annotations
-
Utilisation de fichiers properties simples pour surcharger les paramètres par défaut
-
On peut quand même utiliser des fichiers de configuration XML en faisant un effort
-
2.3. Les dépendances d’une application Spring Boot
Spring Initializr permet de choisir les dépendances/frameworks à utiliser pour la conception d’une application certaines dépendances sont presque indispensables à la création d’une application Web, d’autres sont optionnelles et peuvent être choisies plus tard.
-
Les dépendances indispensables :
-
Spring Boot DevTools: permet des redémarrages rapides des applications, le rechargement temps réel des configurations pour une expérience de programmation plus fluide. Mais consomme un peu plus de ressources. -
Spring Web: pour construire des applications Web MVC, y compris RESTFUL. Utilise Apache Tomcat comme conteneur de servlets par défaut. -
ThymeleafouApache Freemarker: exemples de moteurs de templates pour gérer les pages HTML, ne pas en choisir plus d’un dans un projet, autant que possible.
-
-
Les dépendances optionnelles :
-
Spring Data JPA: pour gérer la persistance des données dans une base SQL -
Apache Derby DatabaseouH2 DatabaseouPostgreSQL DriverouMySQL Driver: pour gérer les accès à une base de données SQL. Nécessaire pourSpring Data JPA. -
Spring Security: framework d’authentification et d’autorisation pour créer des applications sécurisées. Attention dès que ce composant est installé l’application demande une authentification.
-
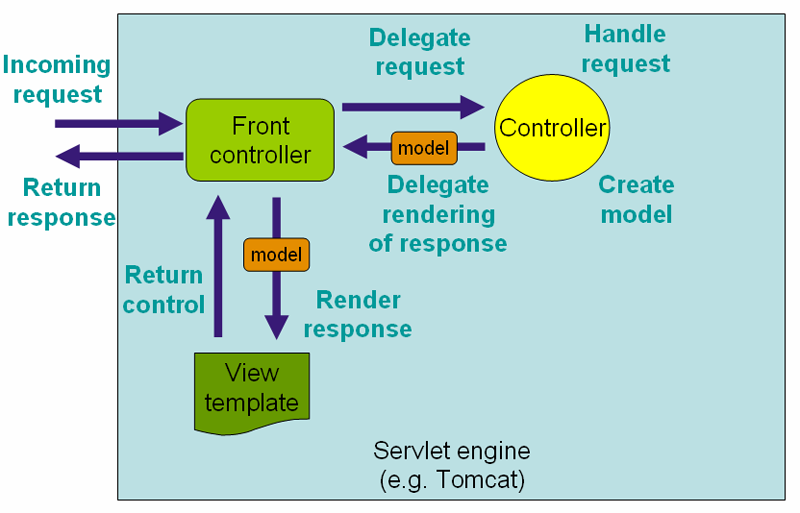
Exemple d’interactions d’une application web MVC (source : https://docs.spring.io
:
2.4. Préparation de votre machine de dev
Rendez-vous Starter app Spring Boot Kotlin afin de valider vos prérequis machine pour le développement web. Consulter le README et suivre les étapes qui vont vous amener à télécharger le projet, l’ouvrir dans un IDE, le compiler et l’exécuter.
2.5. Générer une application Spring Boot
Votre machine est maintenant opérationnelle. Vous pouvez vous engagez dans le développement web avec Spring Boot.
Le moyen le plus simple pour générer une application Spring Boot est de passer par le site https://start.spring.io qui permet de positionner un certain nombre de paramètres et de choisir les dépendances à utiliser.
C’est ce que nous allons voir maintenant.
3. Première application
3.1. Une première application Spring Boot
Nous allons créer une application Spring Boot from scratch (à partir de zéro)
Allez sur : https://start.spring.io
3.1.1. Création du projet
Dans Spring Initializr effectuez les choix suivants :
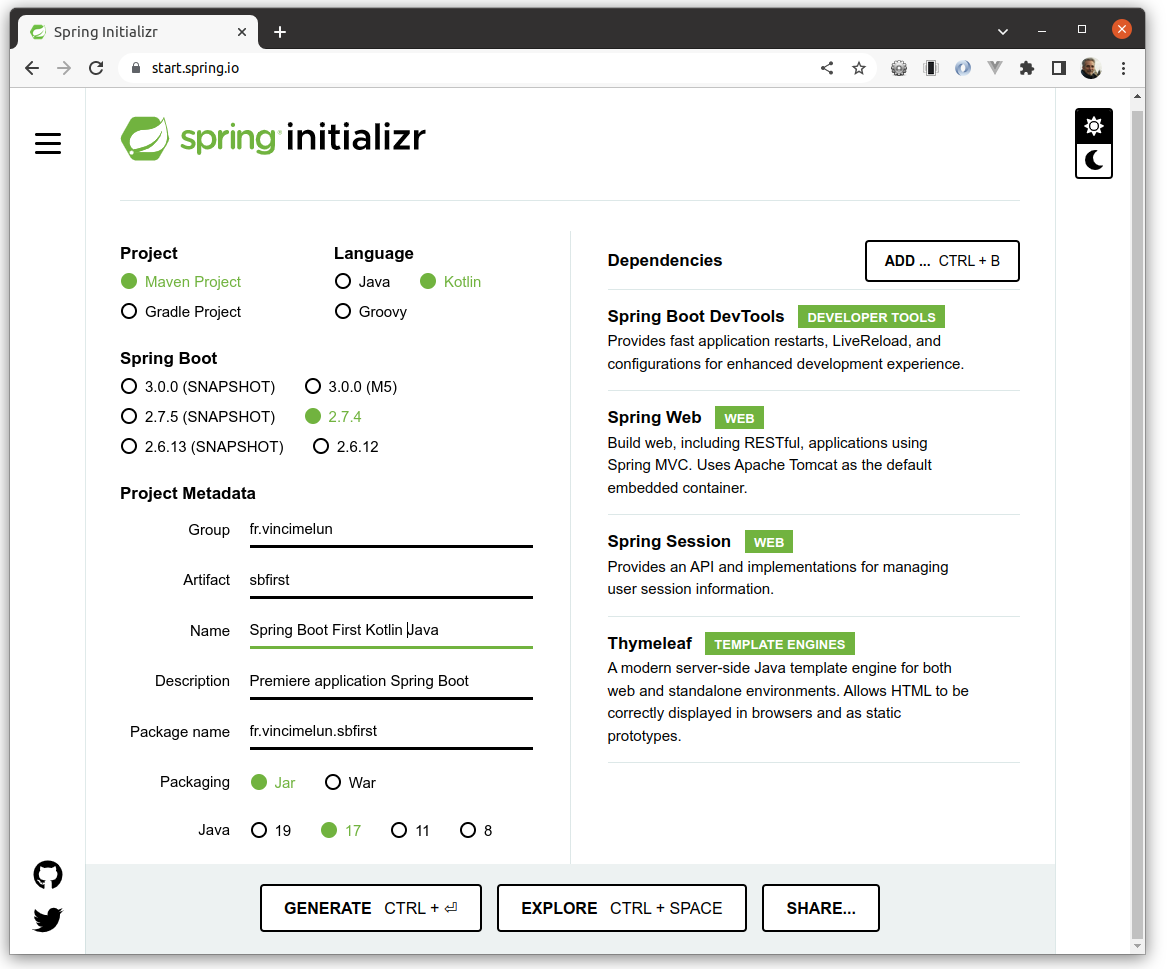
-
Paramètres :
-
Project : Maven Project
-
Language : Kotlin
-
Spring Boot version : 2.7.4
-
Métadonnées du projet :
-
Group : fr.vincimelun
-
Artifact : sbfirst
-
Name : Spring Boot First
-
Description : Première application Spring Boot
-
Package name : fr.vincimelun.sbfirst
-
Packaging : jar
-
Java (JVM) version : 17
-
-
-
Dependencies :
-
Spring Boot DevTools
-
Spring Web
-
Thymeleaf
-
Spring Initilizr génére un fichier .zip, sbfirst.zip, qui contient le projet prêt à l’emploi.
Une fois téléchargé, décompressez-le dans un dossier projets, puis ouvrir le dossier du projet (et non son dossier parent) avec votre IDE.
sbfirst sbfirst
├── .gitignore
├── HELP.md
├── mvnw
├── mvnw.cmd
├── pom.xml (1)
└── src
├── main
│ ├── kotlin
│ │ └── fr
│ │ └── vincimelun
│ │ └── sbfirst
│ │ └── SpringBootFirstApplication.kt (2)
│ └── resources
│ ├── application.properties (3)
│ ├── static (4)
│ └── templates (5)
└── test
└── kotlin
└── fr
└── vincimelun
└── sbfirst
└── SpringBootFirstApplicationTests.kt
| 1 | Fichier Maven définissant le projet |
| 2 | L’application principale (fonction main) |
| 3 | Le fichier de configuration principal de l’application |
| 4 | Le dossier pour stocker les éléments fixes comme les images ou les feuilles de style css |
| 5 | Le dossier de stockage des templates Freemarker ou Thymeleaf |
La classe principale de l’application ressemble à celles qu’on peut écrire pour n’importe quelle application en mode ligne de commande : une fonction main statique qui permet d’instancier et de lancer l’application.
package fr.vincimelun.sbfirst
import org.springframework.boot.autoconfigure.SpringBootApplication
import org.springframework.boot.runApplication
@SpringBootApplication
class SpringBootFirstApplication
fun main(args: Array<String>) { (1)
runApplication<SpringBootFirstApplication>(*args) (2)
}| 1 | Fonction main de l’application |
| 2 | Construction et lancement de l’application |
Le fichier application.properties est vide, il ne contiendra que les éléments particuliers à la configuration de l’application comme les informations de connexion aux bases de données, ou la configuration du moteur de templates. Par défaut tout doit fonctionner sur les conventions.
3.2. En cas de problème
L’application utilise Apache Maven pour la gestion de ses dépendances.
Si vous utilisez des postes informatiques d’une organisation dont les connexions réseaux sont filtrées par un proxy, il vous faudra renseigner les données du proxy auprès de Maven.
Pour cela vous devez comprendre comment fonctionne Maven : Par défaut, les librairies dont dépend une application sont stockées dans un dossier nommé .m2, à la racine du compte utilisateur (le home directory).
La solution consiste alors à créer un fichier nommé settings.xml à la racine de .m2, dont le contenu est basé sur ce schéma
~/.m2/settings.xml (source : https://maven.apache.org/guides/mini/guide-proxies.html)
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 https://maven.apache.org/xsd/settings-1.0.0.xsd">
<proxies>
<proxy>
<id>myproxy</id>
<active>true</active>
<protocol>http</protocol>
<host>proxy.somewhere.com</host>
<port>8080</port>
</proxy>
</proxies>
</settings>Remarque : le protocole http est celui utilisé pour atteindre le proxy. À modifier le cas échéant.
Voir aussi File>Settings>Proxy
Voir aussi File>Invalide Caches… puis restart
3.3. Un contrôleur avec Model et View (Thymeleaf+HTML)
Un contrôleur est une classe qui est annotée avec @Controller et qui contient des méthodes associées à des URI, ces methodes peuvent être associée à des annotations comme @GetMapping, @PostMapping, … ou @RequestMapping plus générique. Les paramètres passés à ces méthodes sont variables et interprêtés par le moteur de Spring MVC.
Par convention les contrôleurs sont créés dans le package controller de l’application
package fr.vincimelun.sbfirst.controller
import org.springframework.stereotype.Controller
import org.springframework.ui.Model
import org.springframework.ui.set
import org.springframework.web.bind.annotation.GetMapping
@Controller
class MainController { (1)
@GetMapping("/") (2)
fun index(model: Model): String { (3)
model["title"] = "Hello world !" (4)
return "main/index" (5)
}
}| 1 | Par convention, les classes contrôleurs sont préfixées par Controller. |
| 2 | Route correspondant pour la méthode GET et l’URI / |
| 3 | Pour passer des données au template associé à l’URI, il suffit de déclarer un objet de type Model dans les paramètres de la méthode. Attention cet objet est instancié par Spring, il n’y a qu’à l’utiliser. On peut considérer un objet de type Model comme un Map. |
| 4 | Ajoute une valeur au modèle. L’index title sert de clé pour y loger une valeur (ici la chaine de caractère "Hello world !") |
| 5 | Nom du template associé, sans son extention .html |
<!doctype html>
<html lang="fr" xmlns:th="http://www.thymeleaf.org"> (1)
<head>
<meta charset="UTF-8">
<title th:text="${title}">Titre du document</title> (2)
</head>
<body>
<h1 th:text="${title}">Un titre</h1> (3)
</body>
</html>| 1 | Ajout de l’espace de nom du template thymeleaf - attribut de la balise html |
| 2 | Le title du header est défini par la variable $Spring Boot Starter présente dans le contexte. La valeur actuelle Titre du document est fictive, placée ici en guise de documentation, car elle sera remplacée par la valeur de l’expression th:text="$Spring Boot Starter" inscrite en tant qu’attribut de la balise h1. |
| 3 | Dans le body, la balise h1 est définie de la même manière. La valeur de $Spring Boot Starter est définie par la méthode index de MainController. |
|
L’expression D’autres expressions |
Lancer l’application et tester : localhost:8080/
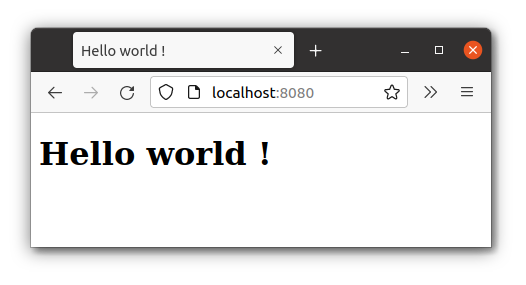
3.4. Un contrôleur sans Model ni View
Certains contrôleurs ne répondent pas au client HTTP avec du contenu HTML. Dans ce cas, la méthode peut se charger de retourner directement du contenu, qu’il faut alors typer (sans passer par un objet Model ni View). Exemple.
@GetMapping("/hello")
@ResponseBody (1)
fun hello(response: HttpServletResponse, request: HttpServletRequest): String {
response.contentType = "text/plain" (2)
response.characterEncoding = "UTF-8"
var nom: String = request.getParameter("nom") ?: "Inconnu"
return "Hello $nom\n"
}| 1 | La méthode prévient le contrôleur principal qu’elle se charge de répondre directement, sans passer par un objet Model et View. |
| 2 | Prévenir le client du type de document retourné, comme, par exemple, text, audio, video, image…
|
3.5. Gérer les données d’entrée
Maintenant que nous avons vu comment concevoir un contrôleur et une vue associée, intéressons-nous à la gestion des données transmises (initiation)
Conformément à l’architecture applicative 3 tiers web, c’est une méthode dite contrôleur qui prend en charge l’exploitation des données transmises par le client HTTP (le tiers distant qui est à l’origine de l’interaction)
| Terminologie : les méthodes associées à des Routes dans une classe Controller sont appelées méthodes d’action ou méthodes contrôleur. Par extension, on nomme parfois de telles méthodes des contrôleurs, et leur classe des "classes contrôleur". |
3.5.1. Auto-injection de l’objet HttpServletRequest
Pour accéder aux données transmises avec la requête HTTP, le contrôleur principal qui appelle les (méthodes) contrôleurs, a la possibilité de passer en argument un objet de type javax.servlet.http.HttpServletRequest (entre autres)
Un objet de la classe HttpServletRequest détient les informations transmises par le client HTTP à l’origine de la requête (par exemple en provenance d’un navigateur à l’autre bout de la planète)
Un contrôleur qui a besoin d’exploiter les données du cleint HTTP devra simplement déclarer, dans ses paramètres, le ou les objets dont il a besoin. Un objet de la classe HttpServletRequest est riche d’information (IP du client, les données transmises…). Il existe d’autres types d’objets plus spécialisé (Session, …)
| Le mécanisme qui consiste à fournir des objets en argument est appelé injection de dépendance : c’est une des façons de réaliser l’inversion de contrôle par les frameworks (IOC). Voir à ce sujet wikipedia IOC inversion of control |
C’est par l’intermédiaire de cet objet de type HttpServletRequest que nous pourrons accéder aux données brutes de la session utilisateur. D’autres façons de faire seront présentées ultérieurement.
@GetMapping("/hello")
fun hello(request: HttpServletRequest): String { (1)
// code ici
}| 1 | On remarquera, dans la signature de la méthode, la déclaration du paramètre permettant à Spring de réaliser l’injection. |
3.5.2. Données d’entrée implicites
Ce sont les données transmises automatiquement par le tiers client, dans la partie entête HTTP. Ces données sont accessibles via l’objet HttpServletRequest qui dispose de méthodes bien pratiques pour les interroger.
-
getMethod(): StringReturns the name of the HTTP method with which this request was made, for example, GET, POST, or PUT. -
isRequestedSessionIdFromCookie(): BooleanChecks whether the requested session ID came in as a cookie. -
getLocale()Returns the preferredLocalethat the client will accept content in, based on the Accept-Language header. If the client request doesn’t provide an Accept-Language header, this method returns the default locale for the server. -
getCharacterEncoding()Returns the name of the character encoding used in the body of this request. This method returns null if the request does not specify a character encoding -
getRemoteAddr()Returns the Internet Protocol (IP) address of the client or last proxy that sent the request. -
…
voir API Request
3.5.3. Données d’entrée explicites
Typiquement ce sont celles volontairement transmises par la requête HTTP
Données sous la forme de couples clé=valeur
-
de type
GETcomme composantes QueryString de l'URL -
de type
POSTformulaire HTML ou non, passé dans le corps de la requête HTTP,
Exemple. Soit l’URL suivante (un GET) :
http://51.68.231.195:8080/hello?nom=Django
Côté application web, la méthode prenant en charge cette route devra interroger la donnée d’entrée nommée nom (clé du couple nom=Django)
@GetMapping("/hello")
fun index(request : HttpServletRequest): String {
var nom: String = request.getParameter("nom") ?: "" (1)
// faire quelque chose avec nom
}| 1 | La méthode getParameter permet, comme son nom l’indique, de récupérer l’éventuelle valeur d’un paramètre (rend null sinon)
Nous utilisons ici l’opérateur Elvis ( |
Cette façon de faire convient aussi bien aux données en provenance de la query string (méthode GET) que celle en postée par un formulaire (méthode POST par exemple).
La méthode getParameter ne doit être utilisée que si on est sûr d’obtenir, au plus une seule valeur. Dans le cas contraire nous utiliserons la méthode getParameterValues qui retourne un tableau de String.
|
|
Une autre façon d’opérer est de déclarer la valeur attendue en tant que paramètre typé du contrôleur. Pour cela nous devons faire usage de l’annotation Exemple
|
Données intégrées à l’url
Exemple d’appel. On souhaite modifier une donnée :
https://quizbe.org/question/edit/42 (1)
| 1 | Attention, l’URL n’est pas https://quizbe.org/question/edit?id=42 |
Pour extraire les parties variables de l’URL, nous les encadrons d’accolades et utilisons l’annotation @PathVariable
@GetMapping("/article/detail/{id}")(1)
fun detail(@PathVariable id: Long, model: Model): String { (2)
// println("id = ${id}")
val article : Article = articleRepository.findByIdOrNull(id)
?: throw ResponseStatusException(HttpStatus.NOT_FOUND, "Article not found")
model["title"] = "Article"
model["article"] = article
return "article/detail"
}| 1 | La route contient une partie variable, placé entre accolades { } (ici id est le nom du paramètre). Exemples d’arguments : /question/edit/42 ou /question/edit/352. |
| 2 | Reprise de la partie variable de l’url comme paramètre typé (Long, String, …) de la méthode (attention, la correspondance se base sur le nom inscrit entre { } dans la route) |
Il est dans ce cas très facile de récupérer les valeurs en question, car elles sont passées automatiquement en tant qu’argument de la méthode !
3.6. Travaux Pratiques - Le contrôleur et la vue (initiation)
| Attention à bien respecter les conventions de nommage usuelle https://kotlinlang.org/docs/coding-conventions.html |
-
Ajouter une nouvelle classe
controllernommé SioController disposant d’une méthode contrôleur index. Faire en sorte que l’index présente le message « Hello world ! » à l’utilisateur (vue thymeleaf), suivi de la langue préférée du client (donnée implicite) ainsi que son adresse IP (idem).
-
Ajouter la méthode hello ci-dessous, qui reçoit en paramètre un nom, et retourne le message « Hello <nom> ! (<n> caractères) » (où <nom> est remplacé par l’argument reçu, et <n> le nombre de caractères du nom)
-
Faire en sorte que le nom soit présenté à l’utilisateur soit capitalisé.
Comme c’est un travail de présentation, il est logique de dédier cette tâche à la logique de présentation. Vous chercherez comment le faire en
tyhymleaf.En cas d’absence de données d’entrée, si aucun nom n’est passé à hello, le message 'Hello Inconnu !' (sans le nombre de caractères) est présenté.
-
Modifier la méthode d’action hello afin que, si le nom transmis est de la forme prenom*nom (avec une étoile entre le prénom et le nom), le message soit présenté selon l’exemple ci-dessous : http://localhost:8080/hello/django*reinhardt
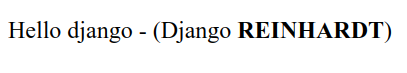
s aucune étoile n’est présente dans l’argument de l’url,
le fonctionnement de hello devra rester conforme à l’attendu de la question précédente (soit "Hello Django (6 caractères)" si, par exemple, seule la valeur "Django" est transmise)
|
⇒ à vous de déterminer le travail qui devra être réalisé côté contrôleur et côté logique de présentaiton (thymeleaf)
-
(plus difficile) Ajouter un flash message (message qui s’affiche qu’une seule fois), qui retourne à l’utilisateur un message de bienvenue avec son IP lors d’une première connection à la route
/hello(et donc à sa méthode d’action liée), pour une même instance de navigateur. Conseil : Afficher dans un premier temps le message, puis mettre sous condition la création du message en gérant une donnée de session utilisateur.
l’objet Session peut être retrouvé via un objet HttpServletRequest. Vous trouverez un exemple ici : https://github.com/ldv-melun/sbfirst)
|
3.7. Challenge
Concevoir une application web répondant aux spécifications suivantes :
-
L’utilisateur cherche à trouver un nombre retenu par l’application de façon « aléatoire », sur une plage d’amplitude allant de zéro à XXX (à definir).
-
Chaque nombre sera représenté par une cellule td d’un tableau html.
-
Lorsque l’utilisateur soumet une proposition (clique sur une cellule/nombre), l’application répond « valeur trop petite », « valeur trop grande » ou « Trouvé ! ».
Durant les tentatives, l’application montre les cellules déjà sélectionnées par l’utilisateur (prévoir une classe CSS dédiée). La partie s’arrête lorsque l’utilisateur a trouvé le bon nombre.
-
Lorsque que le nombre est trouvé, l’application affiche un des messages suivants :
-
« Vous avez de la chance !» si le nombre d’essais du joueur est inférieur au nombre optimal (à déterminer après avoir étudié le principe de la recherche dichotomique - lien wikipédia ci-dessous).
-
« Votre stratégie a été la bonne » si le nombre d’essai du joueur est égale au nombre optimal.
-
« Vous avez débordé de n tentatives » où n est le nombre de tentatives au-delà du nombre optimal.
-
-
L’utilisateur pourra relancer autant de parties qu’il le souhaite.
-
Comme il se doit, l’application sera capable de gérer plusieurs utilisateurs/parties en même temps.
| Il est possible de réaliser un suivi de session sans rien sauvegarder sur le serveur (les « données de sessions » sont alors transmises au client – et donc portées uniquement par celui-ci). |
Optionnel, pour les plus avancés :
-
L’utilisateur peut étendre l’amplitude de la matrice (dimension du tableau)
3.7.1. Ressources à prendre en compte
-
Recherche dichotomique : https://fr.wikipedia.org/wiki/Dichotomie
4. Introduction (layout avec thymleaf)
4.1. Présentation
Lorsqu’une application web est constituée de plusieurs pages, il est alors de bon usage de conserver une unité de représentation.
Techniquement, cette unité de représentation se base sur :
-
un modèle, connu sous le nom de template ou layout (structuration HTML).
-
un ensemble de règles CSS partagées par l’ensemble des pages
-
[des dépendances de bibliothèques js]
En phase de prototypage, il est fréquent de s’appuyer sur des frameworks CSS (par exemples Bootstrap, bulma )
Ces solutions intègrent de nombreux composants CSS et JS. Ces composants sont destinés au tiers client (navigateur, smartphone…).
Il existe 2 solutions pour distribuer ces composants aux clients tiers :
-
donner aux clients un lien sur le réseau de contenu (CDN content delivery network), pour téléchargement, par exemple http://code.jquery.com/jquery-3.3.1.js
-
servir ces composants à partir du serveur web de l’application (communication HTTP entre le serveur HTTP de l’application et les clients), par exemple http://monapplication.com/js/jquery-3.3.1.js
Dans le cadre d’une application à faible diffusion, la deuxième solution peut être envisagée, de plus elle a le mérite d’assurer la disponibilité des composants (si l’application est disponible, alors ses composants le sont aussi), et, accessoirement, permet au développeur de travailler hors ligne.
4.2. webjars - une solution java
Nous nous placons dans le cas où c’est l’application qui héberge les composants dont auront besoin ses tiers clients.
Initialement, l’application devra donc les obtenir (elle utilisera CDN pour l’occasion). Elle pourrait pour cela utiliser des gestionnaires de version spécilisés comme npm, yarn, bower…), mais il serait dommage de ne pas profiter du gestionnaire de version maven ! C’est ce que permet la solution webjars, qui encapsule les composants client dans un jar. Tout cela se passe côté serveur bien entendu.
Les WebJars sont des librairies à destination des clients-web (par exemple jQuery & Bootstrap), packagées dans un fichier JAR (Java Archive), et disponible via divers gestionnaires d’automatisation de taches, comme maven par exemple.

La définition de la dépendance devra être copiée dans le fichier pom.xml du projet. C’est à partir de cette référence que maven téléchargera dans son dépot local les fichiers en question, et rendra accessibles ces fichiers en les plaçant dans le CLASSPATH du projet (ce qui les rendra accessible à l’IDE).
Pour connaître les instructions de dépendances de composants, aller ici : https://mvnrepository.com/artifact/org.webjars
4.3. webjars - cas bootstrap
[...]
<dependencies>
<!--making dependencies version agnostic
@see https://www.webjars.org/documentation#springboot -->
<dependency>
<groupId>org.webjars</groupId>
<artifactId>webjars-locator-core</artifactId> (1)
<version>0.52</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.webjars/bootstrap -->
<dependency>
<groupId>org.webjars</groupId>
<artifactId>bootstrap</artifactId> (2)
<version>5.2.2</version>
</dependency>
</dependencies>| 1 | Ce composant permet de ne pas renseigner la version des composants dans les instructions d’inclusion du template html. C’est ce document qui se charge de cela. |
| 2 | La dernière version du composant bootstrap (octobre 2022) |
Ces déclarations de dépendances, lorsqu’elle seront évaluées par maven, provoqueront le rapatriement, sur la machine hôte, des ressources inscrites dans le webjars.
Ces ressources seront alors accessibles au projet, via l’IDE, au même titre que des librairies java.
Le développeur pourra donc y faire références à la conception des vues.
4.4. layout - cas thymeleaf
Avec thymeleaf, la conception d’un modèle de présentation (layout ou template) est basée sur la décomposition du modèle en fragments.
Voici une organisation typique de ressources liées à la logique de présentation:
├── application.properties
├── static
│ └── css
│ └── main.css (1)
└── templates
├── admin (2)
│ └── index.html (3)
├── error
│ └── 403.html
...
├── fragments
│ ├── footer.html (4)
│ └── header.html
└─ index.html
| 1 | pour la redéfinition de règles héritées, propre à l’application |
| 2 | en référence au rôle utilisateur prioritairement concerné (ici un admin) |
| 3 | les vues des controleurs sont placées dans un dossier portant le nom racine d’un contrôleur (AdminController) |
| 4 | les fichiers déclarant des fragments (parties réutilisées par les vues) sont logés dans le dossier fragments |
Les différentes pages partagent toutes les mêmes parties header (parties <head> et menu) et footer.
Voici un exemple d’utilisation :
<!DOCTYPE HTML>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Page Admin</title>
<div th:replace="fragments/header :: header-css (title='Admin')"/> (1)
</head>
<body>
<div th:replace="fragments/header :: header"/> (2)
<div class="container">
<h1>Admin index</h1>
</div>
<!-- /.container -->
<div th:replace="fragments/footer:: footer"/> (3)
</body>
</html>| 1 | insertion du fragment header-css (définit dans le fichier header.html) |
| 2 | insertion du fragment header (définit dans le fichier header.html) |
| 3 | insertion du fragment footer (définit dans le fichier footer.html) |
Voyons maintenant des exemples de composants fragment
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:th="http://www.thymeleaf.org"
xmlns:sec="http://www.thymeleaf.org/thymeleaf-extras-springsecurity4">
<head>
</head>
<body>
<div th:fragment="footer"> (1)
<div class="container">
<footer>
© 2022 myapplication.com
</footer>
<script type="text/javascript"
src="/webjars/bootstrap/5.2.2/js/bootstrap.min.js" (2)
th:src="@{/webjars/bootstrap/js/bootstrap.min.js}"> (3)
</script>
</div>
</div>
</body>
</html>| 1 | Un composant est en fait le body d’une page HTML particulière, comportant une déclaration de fragment. |
| 2 | Ceci est un exemple (la doc thymleaf parle de prototype). Sous IntelliJ, pensez à utiliser la complétion automatique (ctrl+ esp) pour l’expression de chemin. |
| 3 | C’est la valeur src qui sera appliquée. Les expressions thymleaf de chemin ou de lien sont encadrées par @{ … }. On notera que nous ne faisons pas appel à une version particulière du composant car c’est webjars-locator-core qui s’en charge. |
<html xmlns:th="http://www.thymeleaf.org">
<head>
<th:block th:fragment="header-css"> (1)
<link rel="stylesheet" type="text/css"
href="/webjars/bootstrap/5.2.2/css/bootstrap.min.css" (2)
th:href="@{/webjars/bootstrap/css/bootstrap.min.css}" /> (3)
<link rel="stylesheet" th:href="@{/css/main.css}" (4)
href="../static/css/main.css" />
<title th:text="${title ?: 'Default title'}"></title> (5)
</th:block>
</head>
<body>
<div th:fragment="header"> (6)
<nav class="navbar navbar-inverse">
<div class="container">
<div class="navbar-header">
<a class="navbar-brand" th:href="@{/}">Spring Boot</a>
</div>
<div id="navbar" class="collapse navbar-collapse">
<ul class="nav navbar-nav">
<li class="active"><a th:href="@{/}">Home</a></li>
</ul>
</div>
</div>
</nav>
</div>
</body>
</html>| 1 | déclaration d’un fragment nommé header-css |
| 2 | prototype de lien bootstrap |
| 3 | expression du lien th:href pour déclaration de l’inclusion |
| 4 | le fichier CSS pour les redéfinitions propres à l’application (ne pas faire référence au dossier static) |
| 5 | définition de la valeur de <title> avec valeur par défaut (opérateur elvis) |
| 6 | déclaration d’un autre fragment dans le même fichier |
4.5. Controleur
Voici un exemple de mise en oeuvre, à minima :
// AdminController
@GetMapping("/admin")
public String admin() {
return "/admin/index";
}Nous avons ici rangé les vues dans des dossiers portant le nom du rôle prioritairement concerné, un parti pris.
4.6. Documentation
-
Documentation générale : thymeleaf documenataion
-
Ne pas passer à côté des classes utilitaires : classes utilitaires - avec exemples
-
Différentes façons d’inclure un fragment : thymeleaf:insclusion de fragments
-
Paramétrer un fragment : fragment paramétré
4.7. Travaux pratiques
4.7.1. Exercice 1
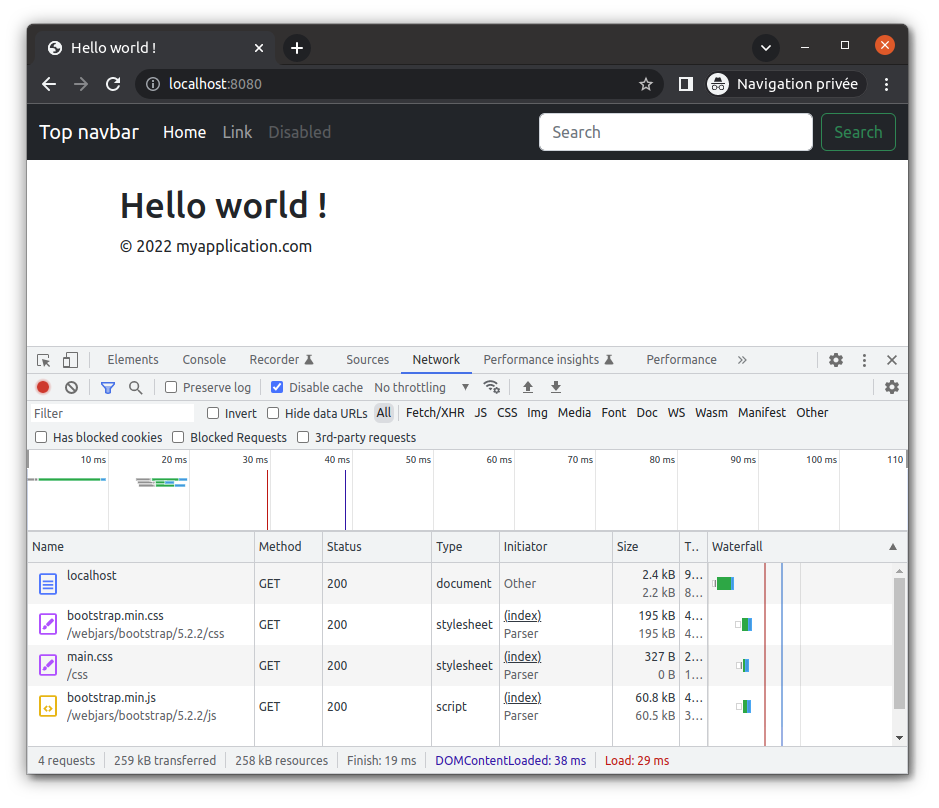
Intégrer bootstrap dans votre application existante, avec le modèle navbar-static disponible ici : https://getbootstrap.com/docs/5.2/examples/navbar-static/
5. Introduction à JPA
5.1. Présentation
JPA est une interface de programmation permettant d’utiliser un modèle objet au-dessus d’une base de données relationnelle.
JPA associe un graphe de classes Java aux tables d’une base de données relationnelle par le biais :
-
de fichiers de configuration xml
-
d’annotations depuis Java 5 (c’est la méthode préférée)
Pour la suite nous utiliserons le modèle suivant :

Dans ce modèle une personne peut écrire plusieurs articles (liste de type Article), et un article est crédité par une seule source (de type Person).
Une application JPA se divise en deux parties :
-
Définir le modèle de données (graphe d’objets)
-
Gérer l’accès aux données (créer, récupérer, modifier et supprimer les données)
5.2. Définir le modèle
5.2.1. Une traduction de l’analyse
Le modèle qui nous intéresse ici est celui centré sur la logique métier du client, les données qu’ils manipulent. Ces données sont regroupées en entités, qui, dans le code, sont représentées par des classes, dites métier, parfois stéréotypées <<entity>> dans les diagrammes d’analyse.
| Il est fort pratique de représenter l’analyse sous la forme d’un diagramme de classes UML, car, en conception (design), l’analyse permet au développeur de se consacrer sur les détails des entités sans perdre le fil de leurs relations. |
5.2.2. Associer une table à une classe, les entités (entities)
Person (sans référence à d’autres entités)@Entity (1)
@Table(name = "Person") (2)
class Person(
@Column(name = "login", unique = true, nullable = false, length = 20) (3)
var login: String, (4)
@Column(name = "firstname", nullable = false)
var firstname: String,
@Column(name = "lastname", nullable = false)
var lastname: String,
@Column(columnDefinition="TEXT")
var description: String? = null,
@Id (5)
@GeneratedValue(strategy = GenerationType.IDENTITY) (6)
@Column(name = "id", nullable = false)
var id: Long? = null) (7)| 1 | @Entity déclare la classe comme un objet persistant
associé par défaut à la table de même nom (à la casse près). |
| 2 | @Table déclare le nom de la table associée à la classe, indispensable
si les deux noms diffèrent (ce n’est pas le cas ici). |
| 3 | @Column permet d’établir la correspondance entre la propriété de la classe
et la colonne de la table, ainsi que certaines règles de validation comme
l’interdiction de nullité, la longueur, le type… |
| 4 | La propriété associée à la colonne de la table (valeur d’attribut). |
| 5 | @Id déclare l’attibut comme clé primaire, au moins un attribut doit
être marqué par cette annotation |
| 6 | @GeneratedValue indique que la valeur est générée automatiquement |
| 7 | Bien que la colonne associée soit déclarée non nullable (c’est une PK), la propriété id l’est ! (son type est Long?) En effet, à la création d’un nouvel objet en mémoire, alors qu’il n’est pas encore persisté (associé à aucune ligne dans la table), l’objet n’a pas encore de valeur d’identifiant de base de données. Cette valeur lui sera attribuée par le SGBD lors de sa sauvegarde dans la base (donc dans un second temps) |
|
Le mécanisme qui assure la correspondance entre une Classe Entity et une Table d’une base de données est appelé ORM (Object Relational Mapping) Un mapping objet-relationnel (en anglais object-relational mapping ou ORM) est un type de programme informatique qui se place en interface entre un programme applicatif et une base de données relationnelle pour simuler une base de données orientée objet. Ce programme définit des correspondances entre les schémas de la base de données et les classes du programme applicatif. On pourrait le désigner par là, « comme une couche d’abstraction entre le monde objet et monde relationnel ». Du fait de sa fonction, on retrouve ce type de programme dans un grand nombre de frameworks sous la forme de composant ORM qui a été soit développé, soit intégré depuis une solution externe. source : https://fr.wikipedia.org/wiki/Mapping_objet-relationnel Ainsi, à une instance d’une classe Entity correspond une ligne d’une table d’une base de données relationnelle. |
5.2.3. Gérer les associations (ManyToOne et OneToMany)
Dans ce modèle un Person peut écrire plusieurs articles, et un article est crédité par une seule personne.

L’association de Article vers Person est de type ManyToOne. Cette même association vue côté Person est de type OneToMany vers Article.
Si l’association est bidirectionnelle, la classe côté ManyToOne (dans notre cas Article) est dite propriétaire (owner) de l’association car sa table associée détient la clé étrangère de la relation. Le côté non propriétaire, ici Person, doit utiliser l’élément mappedBy de l’annotation pour spécifier l’attribut du côté propriétaire. Pour les données en base, le système assure la cohérence des liens entre objets en mémoire. Par contre, en cas gestion mémoire de ces liens par la logique applicative, la cohérence est du ressort du développeur.
@Entity
class Article(
var title: String,
var headline: String,
var content: String,
@ManyToOne (1)
@JoinColumn(name = "credited_to_id") (2)
var creditedTo: Person, (3)
var slug: String = title.toSlug(),
var addedAt: LocalDateTime = LocalDateTime.now(),
@Id @GeneratedValue var id: Long? = null)| 1 | L’annotation @ManyToOne permet de savoir que l’objet annoté doit être retrouvé dans une autre table. Le paramètre FetchType permet de savoir s’il faut immédiatement retrouver l’objet lié (EAGER) ou s’il faut le retrouver seulement lorsqu’il est accédé dans l’application (LAZY). La deuxième option diffère la requête SQL jusqu’à ce que l’application cherche à accéder à l’objet Person |
| 2 | L’annotation @JoinColumn permet à l’application de déterminer quelle colonne dans la table sert de clé étrangère pour retrouver l’objet lié |
| 3 | Si credited_to_id est une clé étrangère et un entier, la propriété associée, nommée creditedTo, est de type Person. |
|
Ne pas confondre clé étrangère et propriété de l’association.
Avec JPA le développeur gère un graphe d’objets, pas une base de données SQL. |
@Entity
class Person(
@Column(name = "login", unique = true, nullable = false, length = 20)
var login: String,
@Column(name = "firstname", nullable = false)
var firstname: String,
@Column(name = "lastname", nullable = false)
var lastname: String,
@Column(columnDefinition="TEXT")
var description: String? = null,
@OneToMany(mappedBy = "creditedTo", cascade = [CascadeType.ALL]) (1)
var articles: MutableList<Article> = mutableListOf(), (2)
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false)
var id: Long? = null)| 1 | @OneToMany indique qu’une instance de Person peut être liée à plusieurs instances de Article, en tant qu’auteur, c’est la propriété creditedTo dans Article qui représente ce lien |
| 2 | Une personne pouvant réaliser plusieurs articles, les références à ses articles sont stockés dans une collection mutable, qui peut être vide. |
5.3. Gérer l’accès aux données, les dépôts (repositories)
5.3.1. Présentation
Si les classes Entity permettent de définir les structures de données et la façon dont les objets sont liés aux tables SQL, elles ne permettent pas de manipuler les tables : créer, lire, mettre à jour ou supprimer des données. En anglais ces actions sont connues sous le nom de CRUD (Create, Read, Update, Delete). Les objets qui permettent de faire des opérations de type CRUD sur une base de données sont appelés des DAO (Data Access Object).
Créer des DAOs est une tâche répétitive et ingrate, 90% du code est
similaire d’un DAO à l’autre. Spring propose une méthode standard pour
gérer les DAOs au travers d’objets, ou plutôt d’interfaces, de type
CrudRepository, PagingAndSortingRepository
` ou `JpaRepository qui hérite de la classe précédente. Dans les cas simples CrudRepository suffit largement.
5.3.2. L’interface CrudRepository
Permet d’effectuer toutes les opérations de base d’un DAO :
-
long count(): compte le nombre d’entités disponibles -
void delete(T entity): supprime l’entité passée en paramètre -
void deleteAll(): supprime toutes les entités -
void deleteById(ID id): supprime une entité avec l’id passé en paramètre -
void existsById(ID id): retourne vrai si une entité avec l’id passé en paramètre existe -
Iterable<T> findAll(): retourne toutes les instances du type -
Iterable<T> findAllById(Iterable<ID> id): -
Optional<T> findById(ID id): retrouve une entité par son id -
<S extends T> S save(S entity): sauvegarde une entité donnée -
<S extends T> Iterable<S> saveAll(Iterable<S> entities): sauvegarde toutes les entités passées en paramètre.
Ci-dessous un exemple de CrudRepository :
package com.example.demo.repository
import com.example.demo.model.Person
import org.springframework.data.repository.CrudRepository
interface PersonRepository : CrudRepository<Person, Long> {
}| L’implémentation de l’interface est réalisée automatiquement par le framework. |
5.4. Exemple de configuration d’un projet Spring Boot avec JPA
# Connexion à la base de données
spring.datasource.url=jdbc:h2:file:c:/db/blog;AUTO_SERVER=true (1)
#spring.datasource.url=jdbc:h2:file:~/db/blog;AUTO_SERVER=true (2)
spring.datasource.driver-class-name=org.h2.Driver (3)
spring.datasource.username=sa (4)
spring.datasource.password= (5)
spring.jpa.hibernate.ddl-auto=create-drop (6)
spring.datasource.initialization-mode=always (7)
spring.h2.console.enabled=true (8)| 1 | Chaîne JDBC de connexion à la base de données, version Windows |
| 2 | La même version Linux ou Mac. ;AUTO_SERVER=true permet une connexion par des tiers comme intellij… (H2 mixed mode) |
| 3 | Driver JDBC à utiliser |
| 4 | Utilisateur pour accéder à la source de données JDBC |
| 5 | Mot de passe de l’utlisateur |
| 6 | Le schéma de la base de données est généré à partir des entités JPA, à chaque exécution de l’application les tables sont supprimées et recrées, l’option create-drop n’est valable que pour la phase de développement, en production on utilise l’option none |
| 7 | Si un fichier `data.sql`est présent, il est automatiquement utilisé pour importer les données qu’il contient dans la base de données |
| 8 | Propre à H2 (driver par défaut). Permet d’accéder à la console H2, une fois que l’application lancée, à l’URL http://localhost:8080/h2-console, il s’agit d’une application web intégrée au moteur H2 permettant de manipuler la base de données. |
Voici un exemple avec MysSql : https://spring.io/guides/gs/accessing-data-mysql/